Mapping antibody–antigen interactions: PhIP-Seq, laser-printed peptide microarrays, and the next-gen cLIFT platform
Article
In the world of immunology, knowing exactly which parts of a protein an antibody recognizes is more than just an academic exercise. This knowledge guides vaccine development, helps refine therapeutic antibodies, results in new diagnostic tests, and uncovers the biological underpinnings of diseases.
Over the past decade, new high-throughput technologies have transformed epitope identification and mapping from a slow, one-target-at-a-time process into a massively parallel, data-rich science. Two approaches have emerged as leaders in this field: Phage Display ImmunoPrecipitation Sequencing (PhIP-Seq) and laser-printed peptide microarrays, developed commercially by PEPperPRINT under the PEPperCHIP® brand.
A third technology is now on the horizon. Combinatorial Laser-Induced Forward Transfer (cLIFT) promises to merge the scale of PhIP-Seq with the chemical flexibility and sensitivity of microarrays, creating a new generation of peptide screening tools.
To understand what this means, let’s look at each technology in turn, compare their strengths and weaknesses, and explore how cLIFT is reshaping the landscape.
PhIP-Seq: Sequencing-powered phage display for proteome-wide epitope discovery
PhIP-Seq is a clever combination of phage display and next-generation sequencing. It begins with a library of bacteriophages, each engineered to display a unique peptide on its outer coat. These libraries can be vast, containing hundreds of thousands or even millions of peptides, often covering entire proteomes.
When this phage library is mixed with a sample such as patient serum, antibodies in the sample bind to the peptides they recognize. The bound antibody–phage complexes are then captured using magnetic beads coated with Protein A or Protein G, which latch onto the antibodies. The DNA inside the captured phages is sequenced, revealing which peptides were present on the surface.
This method excels in scale. Compared to older microarrays or protein arrays, PhIP-Seq offers greater library size and sample throughput. The only real limit to library size is DNA synthesis and cloning feasibility, and modern oligonucleotide library synthesis (OLS) has enabled PhIP-Seq peptides up to ~90 amino acids in length (much longer than the peptides typically used on microarrays). Longer peptides can span multiple linear epitopes or mimic protein fragments, improving the chances of detecting relevant binding.
Notably, PhIP-Seq has been reported to be more scalable in terms of the number of samples and cost per analysis compared to array-based techniques. Once a phage library is created, it can be aliquoted and used to test many samples in parallel, and by barcoding DNA during sequencing, dozens of samples can be multiplexed in one sequencing run. This multiplexing dramatically lowers the marginal cost and effort per sample when screening large cohorts.
The technique’s high sensitivity and breadth make it a powerful discovery tool. For instance, in vaccine research, PhIP-Seq can identify which pathogen peptides elicit strong antibody responses, pointing to potential vaccine targets. In one case, researchers created a PhIP-Seq library of ~120,000 peptides spanning the entire Schistosoma mansoni parasite proteome to find new vaccine candidates, an effort that would have been impractical with traditional methods.
However, the approach does have limitations. Epitope context is one consideration, and phage-displayed peptides are typically linear and lack any post-translational modifications (e.g. phosphorylation or glycosylation) present in natural proteins. Only genetically encoded amino acids are represented, so if an antibody recognizes a modified amino acid or a conformational epitope, PhIP-Seq may miss it.
Another limitation can be library bias and coverage. Ideally, every peptide is equally represented in the phage pool, but in practice, some sequences may propagate or display less efficiently. The outcome of PhiP-Seq also does not provide any information about the strength of an interaction or antibody titers, it only delivers yes/no answers.
With peptides up to ~90 amino acids in length, epitope resolution is not given, since typical epitopes have lengths of less than 10 amino acids. A peptide microarray-based epitope mapping of a single EBV EBNA-1 PhiP-Seq peptide revealed 4 clearly separated epitopes (see figure 1) compared to just one PhiP-Seq hit, which would also have been observed with only one or two underlying epitopes. Accordingly, PhiP-Seq does not provide high-resolution epitope data, and can be blind for individual epitopes. With peptides up to ~90 amino acids in length, PhiP-Seq is rather in between a peptide and a protein microarray.
PhIP-Seq is also technically demanding. It requires phage library handling, immunoprecipitation steps, high-throughput sequencing, and bioinformatics analysis. While specialized service providers are starting to make it more accessible, it still tends to be the domain of well-equipped research labs or dedicated core facilities, making the entry cost and complexity of PhIP-Seq higher relative to array technologies that use more familiar lab workflows.
PEPperCHIP® Peptide Microarrays: Laser-printed peptides for high-precision epitope mapping
The PEPperCHIP® Peptide Microarray platform takes a very different approach: Instead of using biological phages and DNA sequencing, it uses synthetic chemistry and a glass slide to present peptides.
PEPperPRINT’s technology essentially performs high-resolution in situ peptide synthesis on a glass slide using a laser-based printing process. The process combines principles of Solid-Phase Peptide Synthesis (SPPS) with a custom laser printer. Instead of traditional ink, the “printer cartridges” contain a powder of polymer microparticles, each loaded with an Fmoc-protected amino acid building block. At each cycle of synthesis, the printer laser-transfers these amino acid particles in a defined pattern onto a glass slide coated to support peptide coupling. A heat step then melts the particles, releasing the activated amino acids to couple to the growing peptides on the slide. The slide is washed and deprotected, and the cycle repeats for the next amino acid in sequence.
That way, thousands of different peptide sequences can be synthesized in parallel at defined positions on the microarray. This innovative laser printing method allows extremely tight spatial control, enabling high-density peptide arrays to be made efficiently and in high throughput. PEPperPRINT’s platform can produce a custom peptide microarray from a digital library design in as little as a few weeks, essentially “printing” peptides on demand.
An advantage of chemical synthesis is the flexibility of peptide design. Microarrays readily support post-translational modifications and non-standard amino acids in peptides.
For example, laser-printed PEPperCHIP® arrays can include acetylated or citrullinated, D-amino acids (mirror-image peptides), N-methyl amino acids, and even custom synthetic building blocks. This is extremely useful for the analysis of autoantibodies or antibodies directed against pathogens, because many of these antibody epitopes contain post-translational modifications. Peptides with non-natural building blocks like N-methyl amino acids peptide show a higher stability in vivo and are interesting candidates for peptide therapeutics.
Additionally, peptides can be synthesized cyclically on the array to approximate conformational epitopes. This versatility is valuable for mapping antibody binding to complex or structured peptide loops that linear stretches might not capture.
Using a peptide microarray is straightforward and similar in practice to common laboratory immunoassays like ELISA or Western blot, which makes it accessible to a wide range of users. The completed peptide microarray slide is incubated with the sample of interest (e.g. an antibody solution, serum or plasma) so that antibodies bind to any peptide spots containing their complementary epitope. After washing off unbound material, bound antibodies on each spot are detected by a labeled secondary antibody (for example, a fluorescent anti-human IgG). The slide is then scanned to measure fluorescence intensity at each peptide spot, indicating the strength of binding. This produces a quantitative readout for each peptide’s antibody reactivity.
Historically, library sizes have been smaller than for PhIP-Seq, on the order of a few hundred to 5,000 peptides per slide, and peptides are typically shorter (8–20 amino acids).
The shorter peptide length enables a higher epitope resolution, which somewhat offsets the clearly lower library size. In addition, the library of a peptide microarray can be easily adjusted to a specific research topic: You can map antibody epitopes, e.g., against a certain autoantigen or virus proteome, without running a whole bigger library of unrelated peptides with a lower epitope resolution.
Peptide microarrays have found widespread use in epitope mapping and antibody profiling, both in research and industry settings. A common application is mapping linear B-cell epitopes: for example, when developing a new therapeutic antibody, a microarray of overlapping peptides spanning the target protein can identify the precise epitope recognized by the antibody (important for intellectual property and understanding cross-reactivity). Similarly, microarrays are used to map autoantibody epitopes in autoimmune disease sera, which can reveal disease-specific antibody signatures.
PEPperPRINT’s platform has been used in studies ranging from vaccine development to diagnostic biomarker discovery. In a 2024 study, researchers printed over 5,000 peptides covering key proteins of the African swine fever virus to pinpoint which viral regions are targeted by the pig immune system. In another study, peptide arrays displaying citrullinated vs. native peptides helped dissect autoimmune antibody responses in rheumatoid arthritis, highlighting how arrays can compare modified and unmodified epitopes side by side.
The platform’s maturity (PEPperPRINT was founded in 2010 and has built a strong track record with >300 peer-reviewed publications) suggests that laser-printed peptide microarrays are a reliable and established tool, with a growing user base in both academia and biotech.
PhIP-Seq vs. peptide microarrays: Key differences and considerations
Both PhIP-Seq and PEPperCHIP® Peptide Microarrays enable the analysis of antibody–peptide interactions, but their distinct formats confer different strengths.
PhIP‑Seq dominates in library scale and discovery breadth; it enables examination of hundreds of thousands of peptides in a single multiplexed assay.
In contrast, peptide microarrays offer chemical depth and can include post-translational modifications and non-natural amino acids, making them indispensable for probing the nuances of antibody or protein binding. Their design, execution, and data analysis are straightforward, making them accessible for many labs, especially those seeking targeted or hypothesis-driven studies.
Technically, PhIP‑Seq demands sequencing and bioinformatics infrastructure, while microarrays rely on standard fluorescent scanners and image analysis tools. Cost scaling depends on the experiment: PhIP‑Seq scales well across many samples by using the same library again and again; microarrays are most efficient when screening many peptides per sample, but may become expensive with many samples.
Despite papers that claim a high or even superior sensitivity compared to other immunoassays, PhIP-Seq has some serious issues when it comes to sensitivity: Already the first papers reported that the sensitivity for some viruses was lower than expected (about 53% for influenza and 34% for poliovirus). This is in strong contrast to a polio prevalence of >90% and high antibody titers, as e.g. observed with peptide microarrays. And it’s not limited to small viruses like poliovirus, JC virus or Torque Teno virus, it also applies to other viruses like the frequent Epstein–Barr virus.
In a recent study using a PhIP-Seq library with >300,000 peptides, PEPperPRINT screened serum from three patients with Aspergillus mold allergy and three healthy controls. From the PhIP-Seq data, 104 hits were selected—each a 64-amino-acid peptide—and converted into a microarray with overlapping 15 amino acid peptides with the maximum peptide overlap of 14 amino acids for high-resolution epitope data.
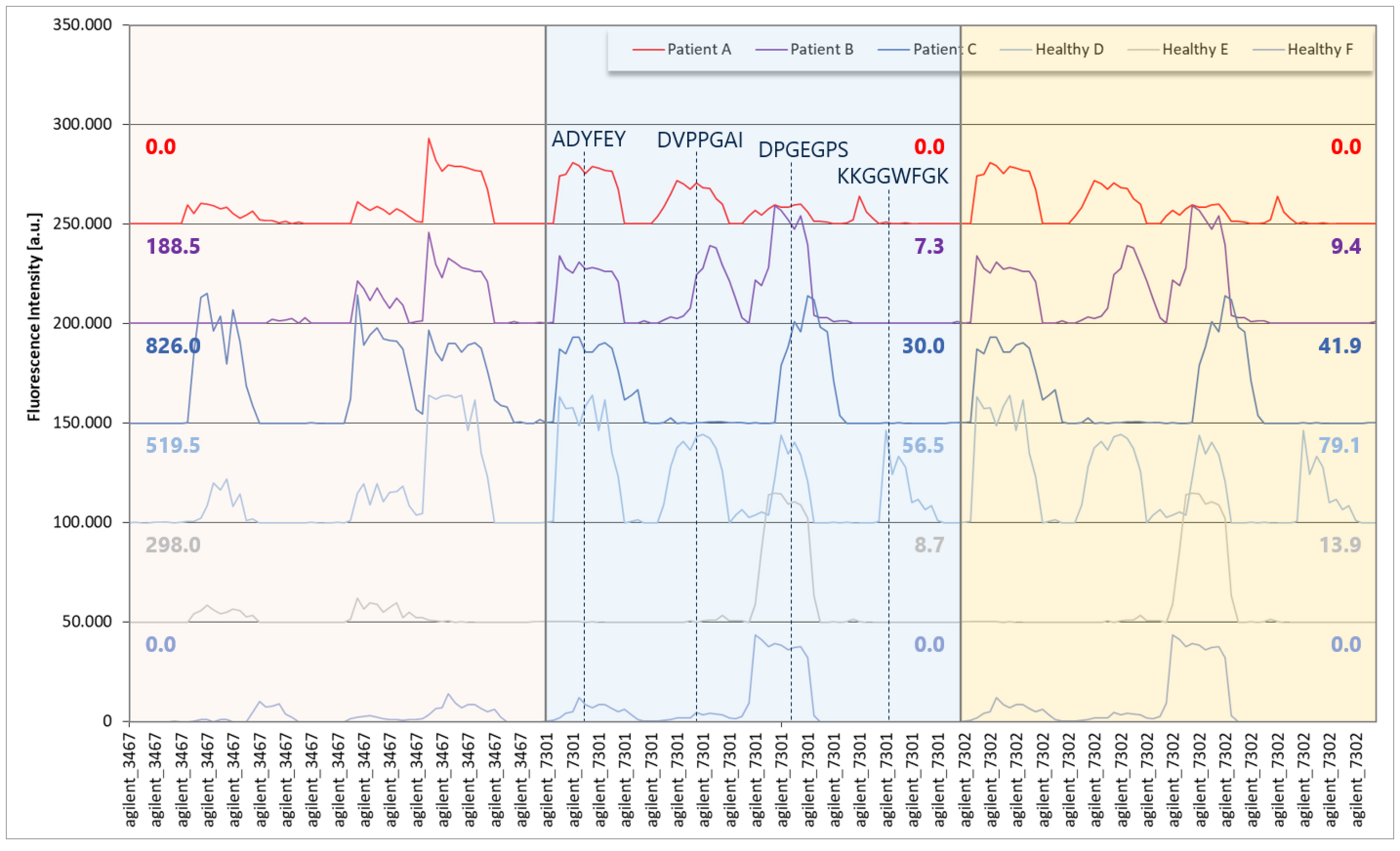
When the same sera were tested on peptide microarrays, strong and clear antibody responses were observed with multiple epitopes per PhIP-Seq hit, with high fluorescence intensities up to 40,000 units (close to the scanner’s 65,000-unit saturation threshold). Yet these responses were not always registered in the PhIP-Seq data: While no PhIP-Seq reactivity was found in Patient A or Healthy F and peptide “agilent_3467” (EBV EBNA1), the peptide microarray data revealed a widely identical reactivity compared to Patient B and Healthy E with 2 and 3 separated epitopes, respectively. A similar finding was observed with PhIP-Seq peptide “agilent_7301” (EBV EBNA1) with no PhIP-Seq in Patient A or Healthy F and a widely identical peptide microarray reactivity compared to Patient B and Healthy E.
This result highlighted that even with the very same PhIP-Seq library, in which all peptides are presented identically, with clearly linear EBNA1 epitopes, strong antibody responses close to the threshold of the microarray scanner and a bigger virus with a high prevalence, some antibody responses could not be detected reliably. By contrast, laser-printed peptide microarrays provided a significantly higher sensitivity, reproducibility and epitope resolution, and also enable the incorporation of post-translational modifications, non-natural amino acids or cyclic peptides to mimic protein conformations to detect binding events that PhIP-Seq cannot.
This comparative table summarizes the key considerations when choosing a technique for epitope identification and analysis:
| PhIP-Seq | Laser-printed microarrays | |
| Library size | 105-106 peptides | Historically up to ~5K (new cLIFT increases this dramatically) |
| Library content | Fixed for a given library | Completely custom |
| Peptide length | 50-90 amino acids | Typically 8-20 amino acids |
| Modifications | None | Wide range of PTMs and non-natural amino acids |
| Sample scalability | Best for large sample numbers | Low to high sample numbers |
| Sensitivity | Variable; prone to false negatives | Very high; including PTMs and conformational epitopes |
| Data analysis | NGS + Bioinformatics | Fluorescence imaging + data quantification software |
| Cost scaling | Efficient for large sample sets | Scales with sample number |
| Ease of access | Requires specialized lab or service | Microarrays and off-the-shelf commercial services available |
Companies may also consider the regulatory and IP aspects of those technologies: synthetic peptide arrays can be manufactured under controlled conditions (PEPperPRINT is ISO 9001 certified, for instance), which might be attractive for pharmaceutical partners. Phage libraries involve biologics and live amplification, which is less typical in a QC-regulated environment. These differences might not affect R&D exploration, but could be relevant if scaling a method toward clinical diagnostics or regulatory submission.
cLIFT technology: Merging proteome-scale screening with unlimited chemical flexibility
The divide between PhIP-Seq and peptide microarrays is narrowing with technological advancements. PEPperPRINT’s cLIFT platform is a prime example of innovation that fuses elements of both worlds.
Launched in 2025, cLIFT builds upon the company’s laser printing foundation in collaboration with academic partners at the Max Planck Institute of Colloids and Interfaces and the Karlsruhe Institute of Technology. The core principle remains using laser pulses to transfer monomer building blocks to the array, but cLIFT introduced refined optics and chemistry that dramatically increased the peptide density and diversity achievable.
By optimizing the transfer of activation reagents and amino acids in tandem, the cLIFT method can synthesize peptides with a wider range of chemistries and at far higher spot density than before. In practical terms, cLIFT has extended peptide microarray capacity by an order of five-fold more peptides on a single microarray compared to their earlier platform - and it now enables, e.g., phosphorylated or even glycosylated amino acids.
This converges the scale of complexity that was once the exclusive domain of PhIP-Seq libraries, effectively bringing array technology into a comparable high-diversity arena.
What does this mean for researchers and industry? Essentially, cLIFT marries the diversity of PhIP-Seq with the precision and flexibility of synthetic chemistry. One can envision creating a cLIFT microarray that contains every peptide from a pathogen’s proteome, achieving in one slide what might otherwise require a phage library.
The ability to print such comprehensive libraries “on-demand” is game-changing for rapid response research. For example, during an outbreak of a new virus, instead of quickly programming a phage library (which still takes cloning and amplification), researchers could synthesize a high-density peptide array covering all viral proteins in a matter of weeks.
Moreover, cLIFT’s strength in incorporating nonstandard monomers means arrays can go beyond nature. This is valuable for therapeutic design, as e.g., D-peptides are protease-resistant and could serve as drug leads if they mimic a peptide or protein binder. These capabilities illustrate how cLIFT isn’t just catching up to PhIP-Seq, but potentially surpassing it in versatility.
In short, cLIFT represents the new generation of peptide microarray technology: it retains the user-friendly, direct assay format of microarrays while adopting the “massive combinatorial library” aspect of phage display. It signals a future where one might perform proteome-scale antibody profiling with a simple slide assay, benefiting both highly technical researchers and non-specialist end-users who need the data.
Ready for the next generation of epitope mapping?
Epitope discovery has come a long way, from classical phage display to PhIP-Seq to laser-printed microarrays. Now, cLIFT sets a new benchmark with unmatched flexibility.
If you’re ready to see how cLIFT can accelerate your own projects, get in touch with us and we’ll be happy to show you.